YOLO Object Detection
Empower your autonomous mobile robots with the speed of "You Only Look Once" architecture. Enable real-time obstacle avoidance, semantic understanding, and precise navigation in dynamic warehouse environments.

Core Concepts
Real-Time Inference
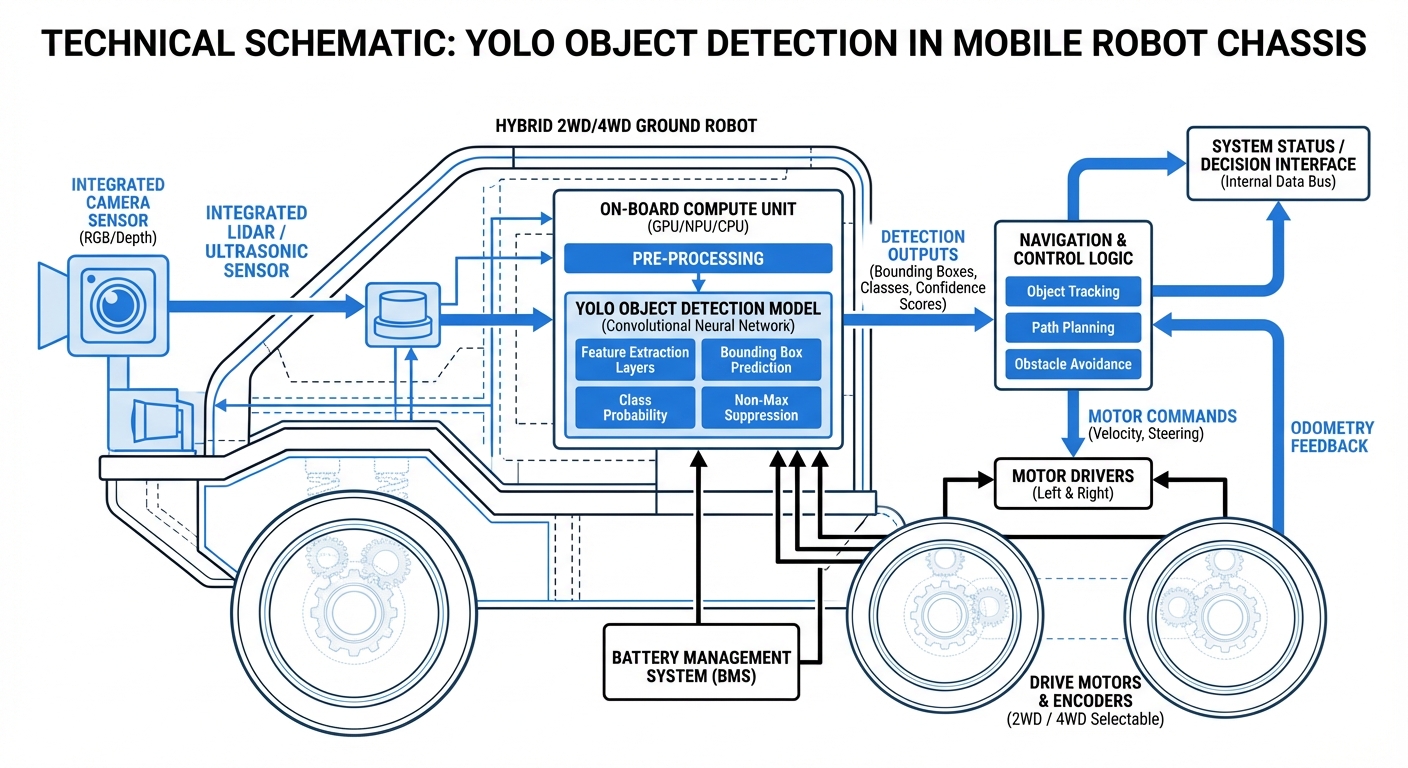
Unlike multi-stage detectors, YOLO processes the entire image in a single pass. This allows AGVs to process video feeds at 30+ FPS, critical for safety at high speeds.
Grid Division
The input image is divided into an S×S grid. If the center of an object falls into a grid cell, that specific cell is responsible for detecting the object.
Bounding Boxes
Each grid cell predicts B bounding boxes and confidence scores. These boxes define the spatial location (x, y, width, height) of obstacles relative to the robot.
Non-Max Suppression
To eliminate duplicate detections of the same object, this algorithm keeps only the bounding box with the highest probability and suppresses overlapping boxes.
IoU Metrics
Intersection over Union (IoU) measures accuracy. It calculates the overlap between the predicted box and the ground truth, ensuring the robot knows exactly where the pallet is.
Class Probability
Simultaneously predicts the class of the object (e.g., "human", "forklift", "shelf"). This allows the fleet management system to apply different logic based on what is detected.
How It Works: The "Single Shot" Advantage
Traditional object detection systems process images in two stages: first generating region proposals, and then classifying them. While accurate, this is often too slow for autonomous robots moving at speed in a busy facility.
YOLO (You Only Look Once) reframes object detection as a single regression problem. It takes the entire image input and passes it through a Convolutional Neural Network (CNN) just once. The output is a tensor containing bounding boxes and class probabilities simultaneously.
This architectural efficiency is why YOLO is the industry standard for edge computing on robots (using hardware like NVIDIA Jetson). It balances the trade-off between inference speed and detection accuracy perfectly for navigation tasks.
Real-World Applications
Human-Robot Collaboration Safety
AGVs utilize YOLO to distinguish between static obstacles (walls) and dynamic actors (humans). By identifying a human specifically, the robot can trigger specialized slowing or stopping protocols that differ from standard obstacle avoidance, ensuring ISO 3691-4 compliance.
Inventory Auditing
While navigating delivery routes, robots equipped with side-facing cameras use YOLO to detect and classify stock on shelves. It can identify empty pallet spaces or verify SKU placement without human intervention, updating the WMS in real-time.
Precise Docking & Handling
YOLO models are trained to detect specific fiducial markers, charging contacts, or pallet pockets. This visual feedback loop allows the robot to make micro-adjustments during the final approach, ensuring a 99.9% successful docking rate.
Foreign Object Debris (FOD)
In manufacturing plants, small debris on the floor can damage AGV wheels. YOLO models trained on "debris" classes allow robots to spot spills, screws, or packaging waste from a distance and reroute around them, alerting maintenance teams automatically.
Frequently Asked Questions
What is the difference between YOLO and R-CNN for robotics?
R-CNN is a two-stage detector that is generally more accurate but significantly slower. YOLO is a single-stage detector that prioritizes inference speed. For mobile robots that need to react to obstacles in milliseconds, YOLO is preferred because it can run at high frame rates (30-60 FPS) on embedded hardware, whereas R-CNN might struggle to reach real-time performance.
What hardware is required to run YOLO on an AGV?
While lightweight versions (like YOLO-Nano) can run on CPUs (like Raspberry Pi), industrial AGVs typically use Edge AI accelerators. The NVIDIA Jetson series (Nano, Orin, Xavier) are the industry standard, providing the CUDA cores necessary to run full YOLO models with low latency and reasonable power consumption.
How does YOLO handle low-light warehouse conditions?
YOLO relies on visual data, so performance degrades in darkness. However, this is mitigated by training the model on low-light datasets or using image augmentation techniques (like adjusting gamma/brightness) during training. For total darkness, YOLO can be combined with thermal cameras or active IR illumination.
Can we train YOLO to detect our specific custom pallets?
Yes, this is a core strength of the architecture via "Transfer Learning." You can take a pre-trained YOLO model and fine-tune it with a smaller dataset of your specific pallets or products. This process is much faster than training from scratch and yields high accuracy for custom facility objects.
How does the robot estimate the distance to the detected object?
YOLO provides a 2D bounding box on the image, but not depth directly. Distance is usually calculated by fusing YOLO output with data from a LiDAR sensor or a stereo depth camera (RGB-D). Alternatively, if the object size is known, the bounding box size can be used to mathematically estimate distance.
Is YOLO integration compatible with ROS/ROS2?
Yes, there are widely supported packages (like `darknet_ros` or `ultralytics_ros`) that wrap YOLO inference engines into ROS nodes. These nodes publish detection topics containing class IDs and bounding box coordinates, which the robot's navigation stack can immediately subscribe to for path planning.
What happens if the robot detects a "False Positive"?
Ghost detections can cause robots to stop unnecessarily. To mitigate this, we use "confidence thresholds" (ignoring predictions below 50-60%) and temporal consistency checks (an object must be detected in several consecutive frames to be considered real). Sensor fusion with LiDAR also helps verify if a visual detection actually has physical mass.
Which version of YOLO should we use (v5, v8, v10)?
For most industrial robotics applications today, YOLOv8 is a strong contender due to its balance of speed, accuracy, and ease of deployment via the Ultralytics framework. However, lighter versions like v5-Nano are still excellent for extremely constrained hardware where battery life is the primary concern.
How much battery power does running vision AI consume?
Running deep learning models is computationally intensive. An NVIDIA Jetson Orin running YOLO might draw 15W-40W depending on the mode. While this is significant, it is usually a small fraction compared to the robot's drive motors. The safety and efficiency gains usually outweigh the slight reduction in runtime.
Can YOLO detect small obstacles like screws or wires?
YOLO historically struggled with small objects, but recent versions utilize feature pyramid networks to improve this. Detection depends heavily on camera resolution and distance. For reliable small-object detection (FOD), the camera must be angled downwards or the robot must move slower to allow for higher resolution processing.
Does the robot need internet access to run YOLO?
No. Inference is performed entirely "at the edge" (on the robot's internal computer). Internet is only required if you wish to upload gathered images to the cloud for retraining the model later to improve performance over time (a process called Active Learning).
How expensive is it to implement YOLO?
The software (YOLO itself) is open-source. The costs come from hardware ($300-$1000 for the compute module + cameras) and the engineering time to label data and integrate the system. Compared to 3D LiDAR safety systems (which can cost $2k+), vision-based navigation is often more cost-effective.
Ready to implement YOLO Object Detection in your fleet?
Discover our range of AI-enabled mobile robots designed for the intelligent warehouse.
Explore Our Robots