Visual SLAM
Simultaneous Localization and Mapping (SLAM) via visual sensors allows autonomous mobile robots to navigate complex, GPS-denied environments. By processing camera data, AGVs can map their surroundings and track their position in real-time with high precision.

Core Concepts
Feature Extraction
The algorithm identifies distinctive points (keypoints) like corners and edges within an image frame to track movement across sequences.
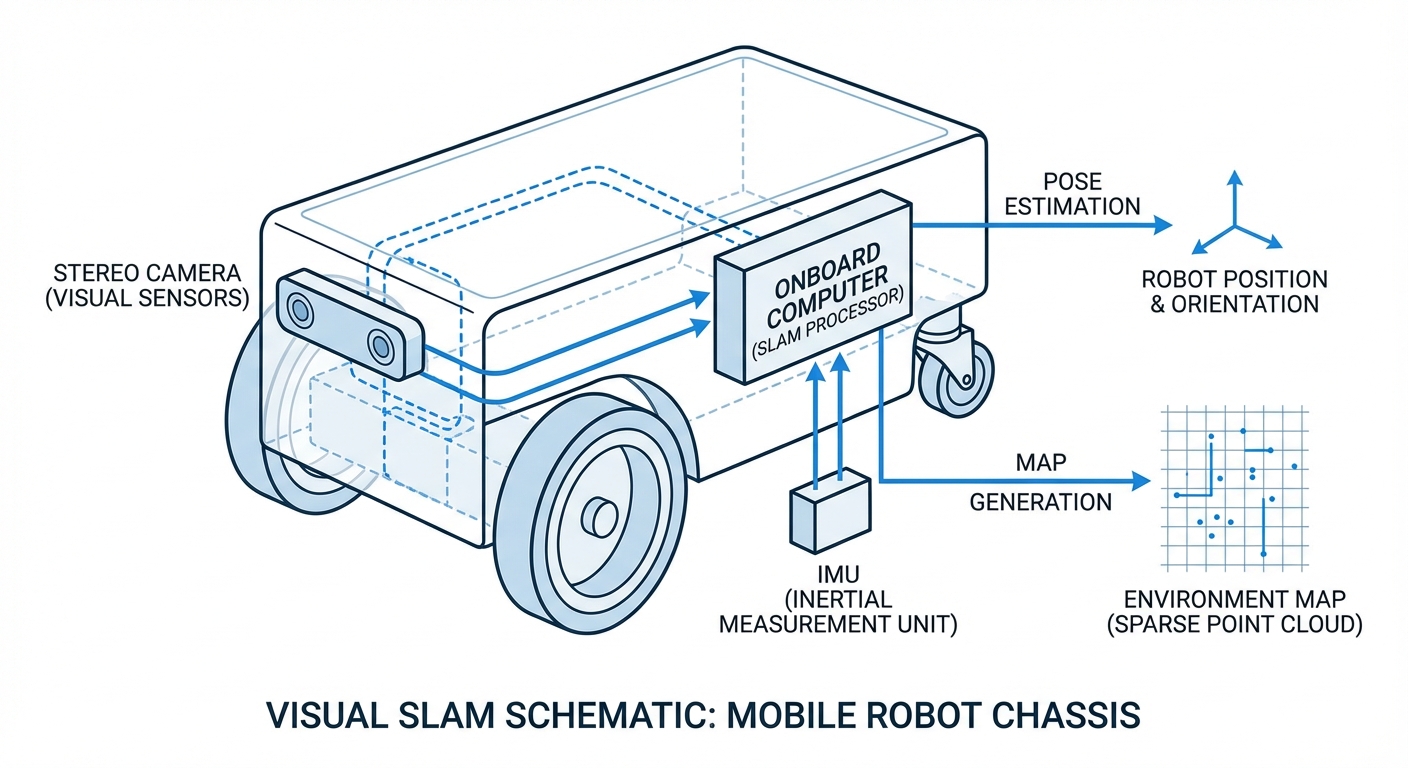
Pose Estimation
Calculates the robot's 3D position and orientation (6-DOF) relative to the starting point by analyzing how feature points move.
Loop Closure
The system recognizes when the robot returns to a previously visited location, correcting accumulated drift errors in the map trajectory.
Bundle Adjustment
An optimization technique that refines the 3D coordinates of scene geometry and the parameters of relative motion to minimize reprojection error.
Visual Odometry
The process of determining the position and orientation of the robot by analyzing the associated camera images frame-by-frame.
Dense Mapping
Unlike sparse mapping which only tracks keypoints, dense mapping reconstructs a complete 3D surface model of the environment for obstacle avoidance.
How Visual SLAM Works
Visual SLAM mimics human vision. As the AGV moves, cameras capture a stream of images. The onboard computer analyzes these images to find anchor points—corners, patterns, or distinct textures—that remain stable between frames.
By triangulating these anchor points from different angles (parallax), the system calculates the depth of objects and the robot's movement relative to them. This data creates a sparse point cloud map that expands as the robot explores.
Crucially, Visual SLAM is often fused with IMU (Inertial Measurement Unit) data. This "Visual-Inertial Odometry" ensures that even if the camera view is temporarily blocked or lacks texture, the robot maintains accurate awareness of its position.
Real-World Applications
Dynamic Warehousing
In environments where racks and pallets move frequently, V-SLAM allows AGVs to adapt to layout changes instantly without needing to reinstall magnetic tape or QR codes.
Retail & Supermarkets
Inventory scanning robots navigate narrow, crowded aisles alongside customers. Visual sensors allow them to detect obstacles and read shelf labels simultaneously.
Hospital Logistics
AMRs delivering medicine and linens navigate long corridors and elevators. V-SLAM provides the semantic understanding required to differentiate between walls, gurneys, and people.
Last-Mile Delivery
Outdoor delivery robots rely on V-SLAM to navigate sidewalks, utilizing sunlight and distinct architectural features for localization where GPS signals might be unreliable.
Frequently Asked Questions
What is the main difference between Visual SLAM and LiDAR SLAM?
LiDAR SLAM uses laser pulses to measure distance, offering high precision in varying light but lacking color data. Visual SLAM uses cameras, which are generally more cost-effective and provide rich semantic data (color, texture) but require more computational power for image processing.
How does Visual SLAM handle low-light conditions?
Low light is a challenge for standard Visual SLAM as cameras struggle to identify features. Modern solutions tackle this by using high-dynamic-range cameras, auxiliary LED lighting on the robot, or fusing the visual data with IMU sensors to bridge gaps in visibility.
Does Visual SLAM work on featureless surfaces like white walls?
Pure Visual SLAM struggles with textureless surfaces because it cannot find keypoints to track. To mitigate this, robots often use stereo cameras which can infer depth via disparity, or project an infrared structured light pattern to create artificial texture.
What is the "Drift" problem and how is it solved?
Drift occurs when small estimation errors accumulate over time, causing the robot's calculated position to diverge from reality. V-SLAM solves this via "Loop Closure," where the robot recognizes a previously visited location and snaps its internal map back to the correct coordinates.
What hardware is required for Visual SLAM?
Essential hardware includes a camera system (Monocular, Stereo, or RGB-D) and a powerful processor (CPU/GPU) capable of running computer vision algorithms in real-time. An IMU is also highly recommended for robustness.
Is Visual SLAM computationally expensive?
Yes, processing video streams frame-by-frame is intensive. However, modern edge computing devices and optimized algorithms (like ORB-SLAM) enable efficient performance on mobile robots without draining battery life excessively.
Can Visual SLAM handle dynamic environments with moving people?
Advanced algorithms can differentiate between static background features (walls) and dynamic objects (people/forklifts). By filtering out moving features from the pose estimation process, the robot maintains accurate localization.
What is the difference between Monocular and Stereo V-SLAM?
Monocular uses a single camera and must move to estimate depth, leaving the absolute scale of the world unknown (scale ambiguity). Stereo uses two synchronized cameras to calculate depth instantly and accurately, determining the true scale of the environment.
How accurate is Visual SLAM compared to GPS?
Visual SLAM is much more accurate than GPS for local positioning, often achieving centimeter-level precision. Unlike GPS, it works indoors, underground, and in urban canyons where satellite signals are blocked.
Can maps created by V-SLAM be saved and reused?
Yes, this is known as "Map Serialization." A robot can map an area once, save it to a server, and other robots in the fleet can download that map to navigate the same space immediately without re-mapping.
Does the camera lens require maintenance?
Since V-SLAM relies entirely on visual clarity, lenses must be kept clean from dust, oil, and scratches. In industrial environments, automated air-puff cleaners or protective housing are often used to maintain sensor integrity.
What is Semantic SLAM?
Semantic SLAM combines mapping with object recognition. Instead of just seeing obstacles, the robot understands "this is a chair" or "this is a door." This allows for higher-level commands like "go to the kitchen" rather than coordinate-based navigation.