Visual Odometry
Visual Odometry (VO) is the process of determining the position and orientation of a robot by analyzing associated camera images. It serves as a critical navigation capability for AGVs in GPS-denied environments, enabling precise localization without expensive infrastructure.

Core Concepts
Feature Detection
The algorithm identifies distinctive points of interest (features) such as corners or edges within a captured image frame to establish landmarks.
Feature Matching
Features are tracked across consecutive frames. By matching these points, the system calculates how pixels have moved relative to the camera.
Motion Estimation
Using the geometric relationship between matched features, the algorithm computes the rotation and translation (6-DoF) of the robot.
Local Optimization
Techniques like 'Bundle Adjustment' refine the estimated trajectory by minimizing the reprojection error across recent frames.
Sensor Fusion (VIO)
For higher robustness, Visual Odometry is often combined with IMU data (Visual-Inertial Odometry) to handle rapid movements or low-texture areas.
Drift Correction
Since VO accumulates error over time, it is often paired with loop closure algorithms or map-based localization to reset the absolute position.
How It Works: The Pipeline
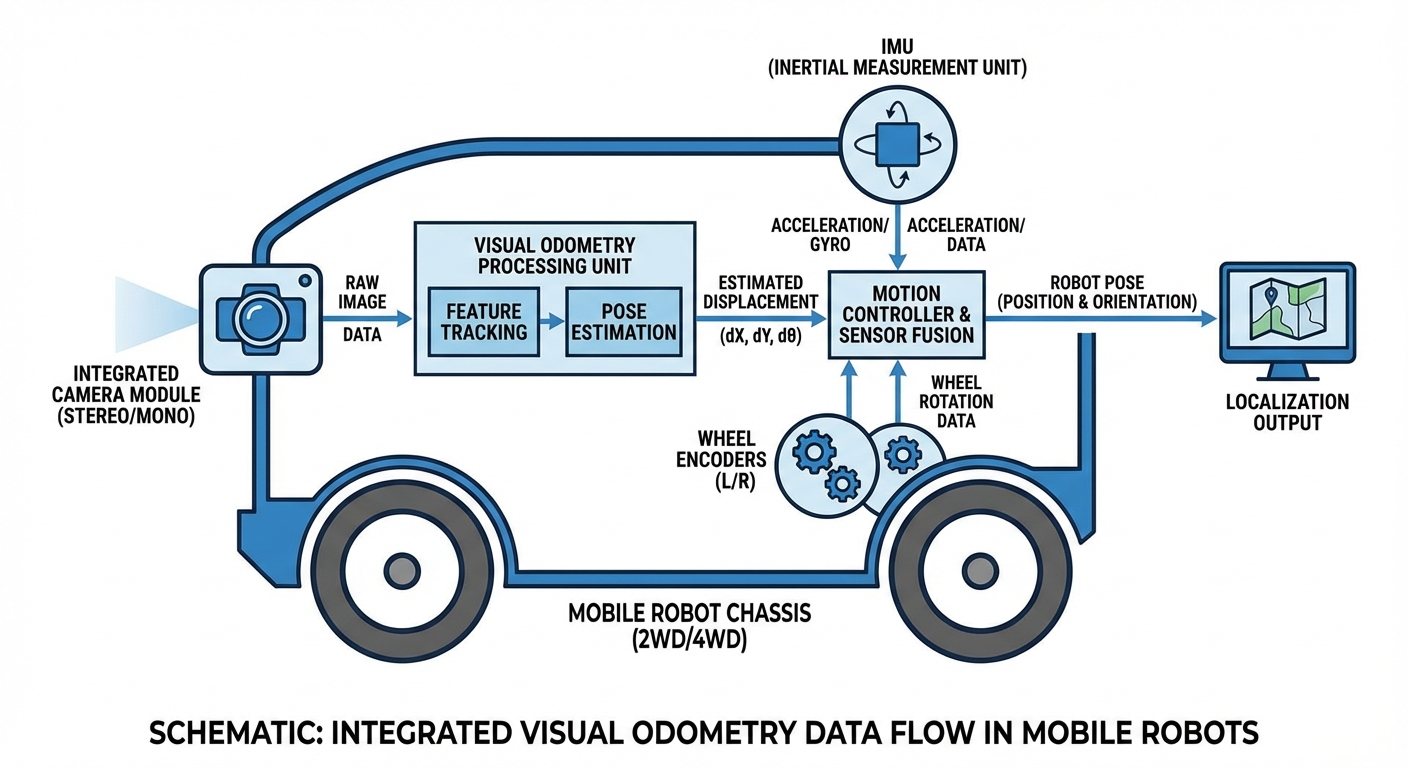
Visual Odometry operates on a "dead reckoning" principle. Unlike GPS which gives an absolute coordinate, VO calculates relative change. The process begins with image acquisition, where the AGV's camera captures a continuous stream of the environment.
The onboard computer processes these images to extract sparse features—high-contrast points like corners or edges. As the robot moves, these features shift position in the camera's field of view. By mathematically analyzing how these points translate and rotate between frame t and frame t+1, the system computes the robot's velocity and trajectory.
This computation happens in milliseconds, allowing the AGV to update its estimated position in real-time. This is particularly crucial for warehouse robots that must navigate narrow aisles where wheel odometry might slip and GPS signals are blocked by ceilings and racking.
Real-World Applications
Dynamic Warehousing
AGVs using VO can navigate environments where layout changes frequently, removing the need for magnetic tape or floor markers.
Service Robotics
Cleaning and delivery robots in hospitals and hotels use VO to localize in long corridors where LiDAR features might be repetitive or sparse.
Last-Mile Delivery
Sidewalk robots utilize visual odometry to handle complex outdoor terrains and GPS multipath errors caused by tall buildings.
Inspection Drones
Aerial drones inspecting tunnels, mines, or under-bridge infrastructure rely on VO for stability when GPS is completely unavailable.
Frequently Asked Questions
What is the difference between Visual Odometry (VO) and V-SLAM?
VO focuses solely on estimating the robot's trajectory (position and orientation) frame-to-frame. V-SLAM (Visual Simultaneous Localization and Mapping) includes VO but also constructs a global map of the environment and performs loop closures to correct drift errors over long periods.
How does Monocular VO differ from Stereo VO?
Monocular VO uses a single camera and cannot determine absolute scale without external data (like speed or object size), meaning the map might drift in size. Stereo VO uses two cameras to calculate depth via triangulation, providing absolute scale and generally higher accuracy, though at a higher computational cost.
What is "Drift" and how do you manage it?
Drift is the accumulation of small calculation errors over time, causing the estimated position to diverge from reality. We manage drift by integrating "Loop Closure" (recognizing a previously visited spot) or fusing VO data with other absolute sensors like LiDAR or occasional GPS updates.
Does Visual Odometry work in low-light conditions?
Standard cameras struggle in low light or darkness because they cannot detect features. However, combining VO with active illumination (IR projectors) or using high-dynamic-range (HDR) sensors can mitigate this. For total darkness, LiDAR is usually preferred.
Why use Visual Odometry instead of Wheel Odometry?
Wheel odometry is prone to errors from wheel slippage, uneven floors, or tire wear, which creates rapid drift. VO tracks the environment itself, making it immune to wheel slip, though it requires more computational power.
What hardware is required to implement VO?
You need a camera (global shutter is preferred to avoid motion blur), a computer or embedded unit (like NVIDIA Jetson or Raspberry Pi 4+) capable of image processing, and ideally an IMU for sensor fusion (VIO).
How does VO handle dynamic environments with moving people?
Moving objects can confuse the algorithm if they are tracked as static features. Modern VO algorithms use outlier rejection schemes (like RANSAC) or semantic segmentation to ignore pixels belonging to moving objects like humans or forklifts.
Is Visual Odometry computationally expensive?
Yes, processing video streams in real-time requires significant CPU/GPU resources. However, optimized "Sparse" VO methods track fewer points to save power, while "Dense" methods map every pixel but require high-end hardware.
What is Visual-Inertial Odometry (VIO)?
VIO tightly couples the camera data with an Inertial Measurement Unit (accelerometer and gyroscope). The IMU handles rapid movements where the camera image might blur, and the camera corrects the IMU's tendency to drift, resulting in a very robust system.
Can VO work in texture-less environments?
VO relies on visual texture (edges, patterns). It struggles in environments like white hallways or glass corridors. In these cases, VIO helps bridge the gap, or structured light cameras (which project their own pattern) are used.
Is calibration necessary?
Absolutely. Precise camera intrinsic calibration (focal length, distortion centers) and extrinsic calibration (camera position relative to the robot center) are critical for accurate trajectory estimation.
How does VO compare to LiDAR-based localization?
LiDAR is generally more accurate and works in total darkness but is significantly more expensive and power-hungry. Cameras are cheaper and provide semantic data (reading signs), making VO a cost-effective alternative for many commercial AGVs.