Semantic Segmentation
Transform standard camera feeds into comprehensive maps by classifying every pixel in an image. Empower your AGVs to distinguish drivable surfaces from dynamic obstacles, racking systems, and personnel with unparalleled precision.

Core Concepts
Pixel-wise Classification
Unlike object detection which draws boxes, segmentation assigns a class label to every single pixel, providing exact object boundaries.
Drivable Area Detection
Critical for AMRs, this isolates floor space from walls and drops, allowing for safe path planning in unstructured environments.
Convolutional Networks
Utilizes architectures like U-Net and DeepLab to process visual data, extracting features and reconstructing precise segmentation masks.
Contextual Understanding
The model understands the relationship between objects, such as knowing that a pallet is usually found on the floor or racking.
Edge Inference
Optimized specifically for NVIDIA Jetson and other edge AI accelerators to run in real-time on battery-powered mobile robots.
Sensor Fusion Ready
Semantic masks can be projected onto LiDAR point clouds, coloring 3D maps with semantic meaning for superior navigation.
How It Works
Semantic segmentation relies on an Encoder-Decoder architecture. The Encoder (often a ResNet or MobileNet) takes the input image and progressively reduces its spatial resolution to extract high-level features—understanding "what" is in the image.
The Decoder then takes these features and upsamples them back to the original image resolution. It reconstructs the spatial details—understanding "where" the objects are.
The final output is a segmentation mask where every pixel is color-coded by category (e.g., Gray for floor, Red for obstacles). This mask is fed directly into the AGV's costmap for immediate path planning decisions.
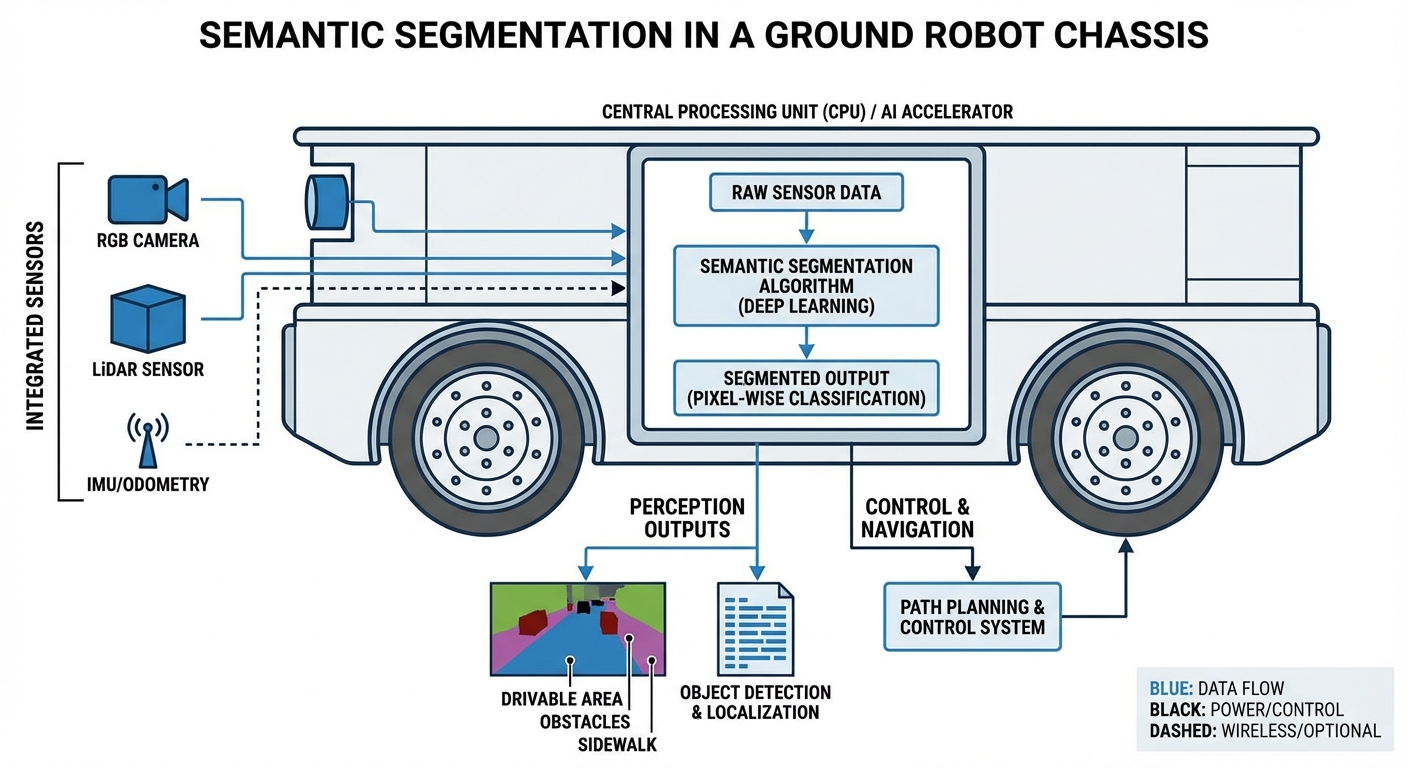
Real-World Applications
Warehouse Free-Space Navigation
In dynamic warehouses where aisles may be partially blocked, semantic segmentation allows robots to identify the exact geometry of the remaining drivable floor, navigating tighter spaces than box-based detection would allow.
Outdoor Last-Mile Delivery
For sidewalk robots, segmentation is crucial to differentiate between paved sidewalks (drivable), grass (non-drivable), and streets (dangerous), ensuring the robot stays strictly within safe pedestrian zones.
Advanced Obstacle Avoidance
Distinguishing between a human, a forklift, and a dropped box. A robot might slow down for a human but stop immediately for a forklift, applying different safety logic based on the semantic class.
Precision Pallet Pocket Detection
Automated Forklifts use segmentation to identify the specific "pockets" of a pallet. This ensures the forks are aligned perfectly even if the pallet is damaged or sitting at a slight angle.
Frequently Asked Questions
What is the difference between Semantic Segmentation and Object Detection?
Object detection draws a bounding box around an object, telling you roughly where it is. Semantic segmentation classifies every pixel within the object's boundary. For robotics, segmentation is superior for navigation because it reveals the exact shape of obstacles and available floor space, rather than just a box that might include empty space.
Does Semantic Segmentation run in real-time on mobile robots?
Yes, but it requires optimization. By using lightweight backbones (like MobileNetV3) and optimizing via TensorRT for NVIDIA Jetson modules, we achieve 30+ FPS. Heavy research models used in academia are often too slow for AGVs, so we prioritize efficient architectures designed for edge inference.
How much training data is required?
Segmentation requires pixel-accurate annotations, which are labor-intensive to create. However, we utilize transfer learning from large datasets (like COCO or Cityscapes) and then fine-tune with a smaller, domain-specific dataset (e.g., 1,000–2,000 images of your warehouse environment) to achieve high accuracy.
Can it handle transparent or reflective surfaces?
This is a classic challenge for LiDAR but easier for vision-based segmentation. With proper training data containing glass walls or polished floors, the neural network learns visual cues (reflections, frames) to classify these surfaces correctly as obstacles, where laser scanners might see "through" them.
What happens if the lighting conditions change?
Drastic lighting changes can affect performance. We mitigate this by using High Dynamic Range (HDR) cameras and applying extensive data augmentation during training (random brightness, contrast, and noise) to make the model invariant to lighting fluctuations in warehouse environments.
What is "Instance Segmentation" and do I need it?
Semantic segmentation treats all "boxes" as the same class. Instance segmentation distinguishes "Box A" from "Box B". For general navigation (don't hit boxes), semantic is sufficient and faster. For manipulation (pick up Box A), you need instance segmentation.
How is the segmentation mask used in ROS Navigation?
The segmentation output is projected from the camera view onto the ground plane. This creates a virtual "laser scan" or is inserted directly into the ROS local costmap layers, marking segmented obstacle pixels as lethal costs and floor pixels as free space.
Can this replace LiDAR entirely?
Visual Semantic Navigation (VSLAM) is gaining traction, but for industrial safety certification, LiDAR is still often required for redundancy. However, segmentation adds the "understanding" that LiDAR lacks, making the system smarter and more robust, even if it doesn't fully replace the depth sensor yet.
What hardware is recommended for running these models?
We recommend NVIDIA Jetson Orin or Xavier series for embedded robotics. These modules possess the tensor cores necessary to run heavy convolutional networks at the framerates required for safe robot motion (typically >10Hz).
How do you handle "unknown" objects not in the training set?
Standard segmentation models force every pixel into a known class. We implement uncertainty estimation—if the model's confidence for a pixel is low (high entropy), we classify it as "unknown obstacle" to ensure the robot treats it with caution rather than misclassifying it as floor.
Is it possible to update the model after deployment?
Yes, through OTA (Over-The-Air) updates. We can collect edge cases where the robot hesitated, annotate those images, retrain the model on the server, and push the optimized weights back to the fleet without hardware changes.