Human Pose Estimation
Moving beyond simple obstacle detection, Human Pose Estimation enables AGVs to identify skeletal landmarks and predict human intent. This advanced perception layer drastically improves safety and efficiency in collaborative human-robot environments.

Core Concepts
Keypoint Detection
The system identifies specific anatomical landmarks (nose, shoulders, elbows, knees) in the camera feed to construct a skeletal map of the human subject.
Bottom-Up Inference
An algorithm approach that detects all body parts in a frame first, then associates them to individual humans, ensuring speed even in crowded environments.
Intent Prediction
By analyzing the vector and velocity of skeletal movement, the AGV calculates if a worker is stepping into its path or moving away, reducing unnecessary emergency stops.
3D Depth Mapping
Integrating RGB data with depth sensors allows the robot to understand the pose in 3D space, determining exactly how far limbs are from the chassis.
Edge Processing
Processing skeletal data locally on the AGV's GPU (NVIDIA Jetson or similar) guarantees low latency, essential for safety-critical maneuvers.
Occlusion Handling
Advanced models can estimate the position of hidden limbs based on visible joints, allowing the robot to track a human even when partially blocked by shelving.
How It Works
The process begins with the AGV's optical sensors capturing a video stream. This input is fed into a Convolutional Neural Network (CNN) specifically trained on human datasets. The network generates 'Confidence Maps' for body part detection and 'Part Affinity Fields' to associate these parts with specific individuals.
Once the skeletal structure is established, the robot's navigation stack interprets the geometry. It doesn't just see a "blob" obstacle; it sees a person facing left, right, or towards the vehicle.
Finally, this semantic understanding informs the local planner. If a human is detected facing the robot with an outstretched arm (gesturing stop), the AGV can prioritize a halt command over standard path deviation logic.
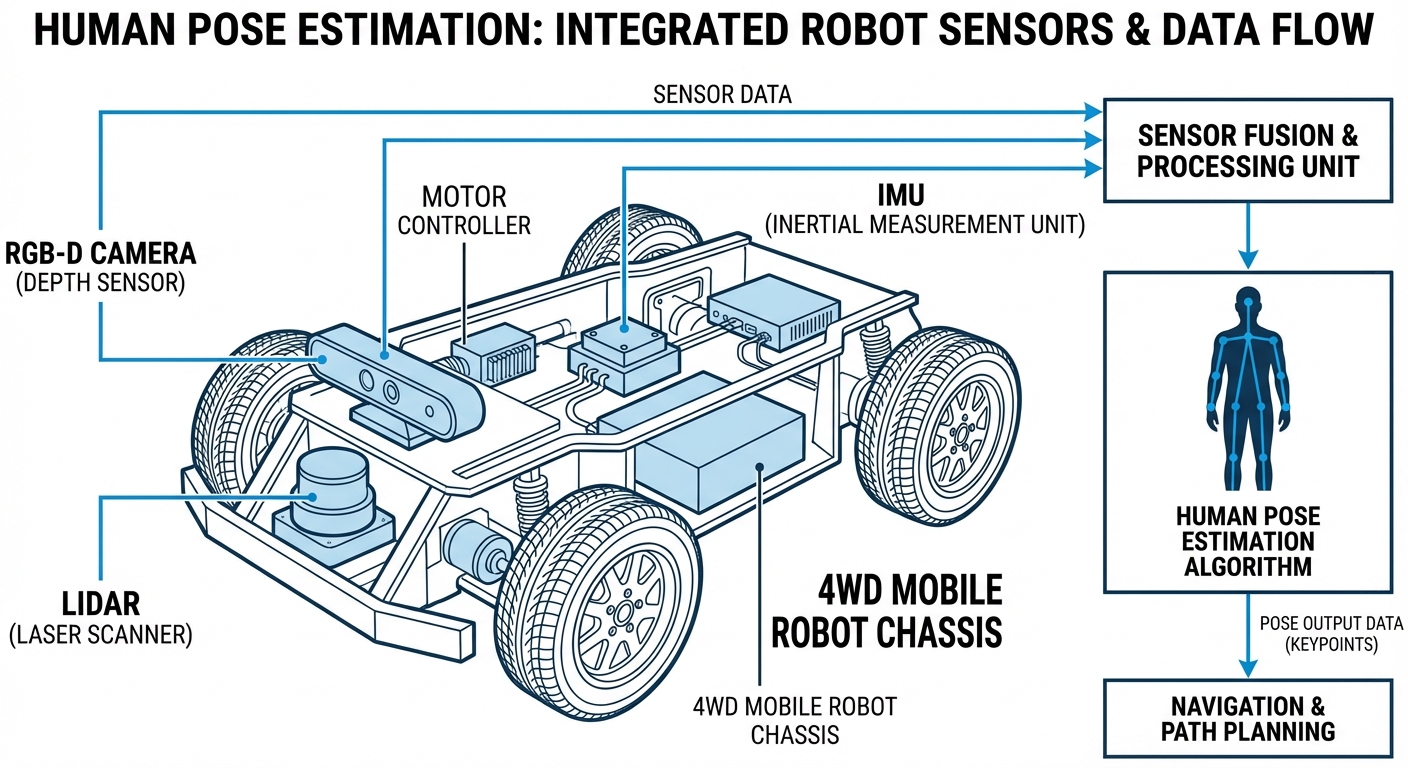
Real-World Applications
Dynamic Warehousing
In facilities where pickers and AMRs share aisles, pose estimation allows robots to navigate tightly around humans who are stationary/picking, without triggering safety stops unnecessarily.
Healthcare Logistics
Delivery robots in hospitals use pose detection to identify patients on crutches or in wheelchairs, automatically increasing the safety buffer zone and slowing down proactively.
Gesture Control
Operators can control AGVs using standardized hand signals (e.g., raised hand for stop, waving motion for follow) without needing physical controllers or tablets.
Collaborative Assembly
In manufacturing, robots can adjust their speed based on the proximity and posture of a technician, enabling safe hand-overs of materials in assembly lines.
Frequently Asked Questions
How does Pose Estimation differ from standard LiDAR obstacle detection?
Standard LiDAR detects the presence and distance of an object but treats a human, a box, and a pillar roughly the same (as points in space). Pose Estimation adds semantic understanding, identifying the object specifically as a human and understanding their posture, orientation, and potential future movement.
What hardware is required to run Pose Estimation on an AGV?
You generally need a high-resolution RGB or RGB-D camera and an edge computing device with GPU acceleration, such as an NVIDIA Jetson Orin or Xavier. Standard microcontrollers used for motor control are insufficient for the heavy matrix calculations required by the neural networks.
Does this technology work in low-light warehouse conditions?
Standard RGB pose estimation degrades in darkness. However, systems using Infrared (IR) cameras or Time-of-Flight (ToF) sensors can maintain pose detection capabilities in low-light or variable lighting conditions typical of 24/7 warehouse operations.
How does the system handle multiple people in the frame?
Modern "Bottom-Up" algorithms (like OpenPose or MediaPipe) are designed to detect all keypoints in an image first and then assemble them into individual skeletons. This allows the AGV to track multiple workers simultaneously without a significant drop in inference speed.
What is the typical latency for pose estimation?
On optimized edge hardware, modern lightweight models (like MobileNet backbones) can run at 30 to 60 FPS with latencies under 30ms. This speed is critical for integrating the data into the robot's real-time safety loop and velocity controller.
Is Pose Estimation safety-rated (SIL/PL)?
Currently, most vision-based AI pose estimation is used as an auxiliary system for efficiency and interaction, not as the primary PL-d safety rating mechanism. It typically layers on top of certified safety LiDAR fields to improve smooth operation, rather than replacing the hard-stop safety loop.
Can it detect workers wearing high-vis vests or PPE?
Yes, but the model must be trained or fine-tuned on datasets that include industrial clothing. Standard datasets (like COCO) usually contain casual clothing. For industrial reliability, training on specific PPE and high-vis gear is recommended to ensure consistent keypoint detection.
What happens if a person is partially hidden behind a rack?
Occlusion robustness is a key feature of modern algorithms. If the head and shoulders are visible, the system infers the presence of the human. The navigation logic should treat the area behind the occlusion as a "potential zone of occupancy" and slow the AGV accordingly.
Are there privacy concerns with filming workers?
Pose estimation abstracts the human into a stick figure (skeleton) of coordinates. The system does not need to perform facial recognition or store video feeds. Processing is usually done instantaneously at the edge, and only the skeletal data coordinates are retained, mitigating GDPR concerns.
How does it integrate with ROS 2?
Pose estimation is widely supported in ROS 2 via packages wrapping frameworks like MediaPipe or OpenPose. The output is typically published as a customized message type (e.g., `PersonList`) containing arrays of joint coordinates, which the navigation stack subscribes to as a dynamic obstacle layer.
What is the maximum detection range?
Range depends on camera resolution and lens focal length. For a standard wide-angle navigation camera, reliable skeletal detection usually occurs within 0.5m to 10m. Beyond that, the person typically becomes too small in pixel count for accurate joint localization.
Does the robot stop if a person is sitting or crouching?
Yes, robust models are trained on various poses including sitting, crouching, and lying down. This is critical for industrial safety, such as detecting an injured worker on the floor or a maintenance technician working on low equipment.