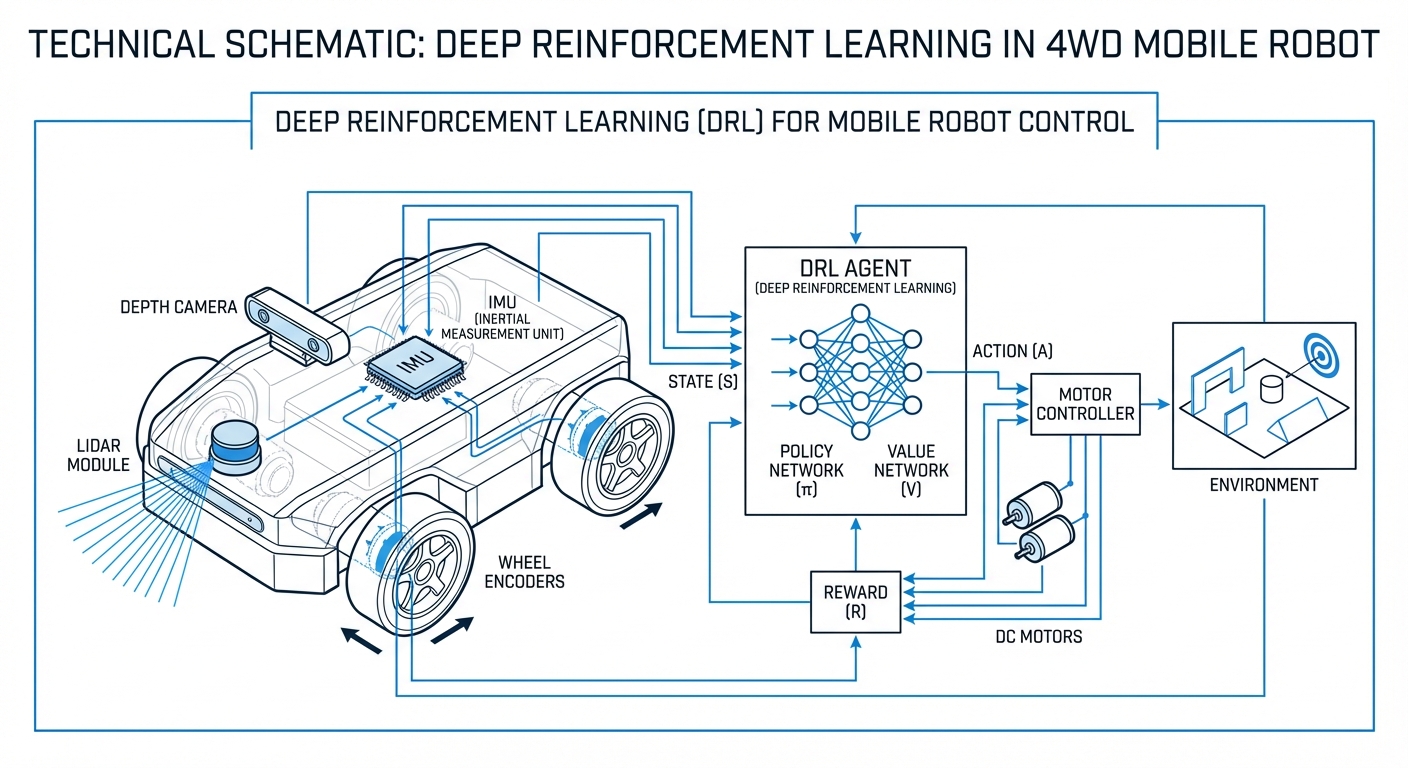
Deep Reinforcement Learning
Revolutionize your autonomous fleet with self-learning algorithms. Deep Reinforcement Learning (DRL) enables AGVs to master complex navigation and manipulation tasks through trial-and-error interaction, surpassing the limitations of traditional rule-based programming.

Core Concepts
The Agent
The mobile robot or AGV itself acts as the agent. It perceives the warehouse environment and makes decisions based on learned policies rather than hard-coded scripts.
State Space
A representation of what the robot sees. This includes inputs from LiDAR, RGB-D cameras, wheel odometry, and battery levels fed into a Neural Network.
Action Space
The set of all possible moves the robot can make. For an AGV, this involves continuous values for steering angle, acceleration, and braking velocity.
Reward Function
The critical feedback loop. The robot receives positive points for reaching a target quickly and negative points for collisions or erratic driving.
Policy Network
A deep neural network (DNN) that maps states to actions. Over millions of training steps, it optimizes the policy to maximize cumulative rewards.
Sim-to-Real
The process of training agents in a physics simulator (like Isaac Sim or Gazebo) to ensure safety, then transferring the learned model to physical hardware.
How It Works
At its core, Deep Reinforcement Learning allows a robot to learn by doing. Unlike traditional SLAM approaches which rely on static maps and rigid path planning, DRL allows for dynamic reaction to the environment.
The AGV observes its current state through sensors. This data is fed into a Convolutional Neural Network (CNN). The network outputs a probability distribution for actions (e.g., "turn left 10 degrees").
Based on the result of that action, the environment provides a "reward." Through algorithms like PPO (Proximal Policy Optimization) or SAC (Soft Actor-Critic), the robot updates its neural weights to encourage actions that yield high rewards and discourage failures.
Eventually, the system converges on an optimal policy, allowing the robot to navigate crowded, unpredictable spaces smoothly without human intervention.
Real-World Applications
Dynamic Obstacle Avoidance
In busy fulfillment centers, people and forklifts move unpredictably. DRL agents learn to anticipate movements and navigate around dynamic obstacles more fluidly than traditional cost-map planners.
Multi-Agent Path Finding (MAPF)
Coordinating hundreds of robots simultaneously. Multi-agent RL enables fleets to self-organize traffic flow, preventing deadlocks and bottlenecks without a central server calculating every move.
Visual Navigation without GPS
For outdoor delivery robots or GPS-denied environments. DRL models can learn to navigate purely based on visual cues and landmarks, similar to how humans orient themselves.
Robotic Arm Manipulation on AGVs
Mobile manipulators use DRL to coordinate the base movement with the arm movement. This allows for "picking while moving," significantly increasing throughput in logistics tasks.
Frequently Asked Questions
What is the difference between Deep Learning and Deep Reinforcement Learning?
Deep Learning typically involves supervised learning where a model is trained on a labeled dataset (e.g., identifying images of pallets). Deep Reinforcement Learning differs because there is no labeled dataset; the robot generates its own data by interacting with the environment and learning from the consequences (rewards) of its actions.
Why use DRL instead of traditional path planning algorithms like A* or Dijkstra?
Traditional algorithms are excellent for static environments but struggle with high uncertainty and dynamic obstacles. DRL agents can generalize better to unseen situations, navigating smoothly around moving humans or machinery without requiring constant re-computation of a global map.
What hardware is required to run DRL on an AGV?
Inference (running the model) is less intensive than training. A modern edge AI computer, such as an NVIDIA Jetson Orin or AGX Xavier, is sufficient to run trained DRL policies in real-time. Training, however, usually requires powerful GPU clusters or cloud infrastructure.
How do you ensure safety if the robot learns by trial and error?
We utilize a "Sim-to-Real" approach. The robot trains in a high-fidelity physics simulator where crashes have no cost. Once the policy is robust and safe, it is deployed to the physical robot, often with a traditional safety layer (like an emergency stop based on proximity sensors) acting as a hard constraint.
What is the "Reality Gap" in robotics RL?
The Reality Gap refers to the discrepancies between the simulation environment and the real world (e.g., friction, sensor noise, lighting). We mitigate this using Domain Randomization, where we vary physical parameters in the simulation during training to make the model robust enough to handle the imperfections of the real world.
Which DRL algorithms are best for mobile robotics?
Continuous control algorithms are standard for robotics. Proximal Policy Optimization (PPO) is popular for its stability and ease of tuning. Soft Actor-Critic (SAC) is also widely used because it is sample-efficient and encourages exploration, which helps in complex navigation tasks.
Does the robot continue learning after deployment?
Generally, no. For safety and predictability, most industrial AGVs run a "frozen" policy that was trained previously. However, data collected during operation can be used to re-train and improve the model in the cloud before pushing a software update to the fleet.
How much data is needed to train a navigation model?
RL is data-hungry, often requiring millions of timesteps. This is why simulation is essential; we can run simulations faster than real-time and in parallel, gathering years of driving experience in just a few days of training time.
What is Reward Shaping and why is it difficult?
Reward shaping is the design of the point system the robot uses to learn. If designed poorly, the robot may find "loopholes" to maximize points without actually performing the task (e.g., spinning in circles to stay safe). Balancing sparsity and density of rewards is a key engineering challenge.
Can DRL handle multi-robot coordination?
Yes, Multi-Agent Reinforcement Learning (MARL) is a specific subfield designed for this. Agents learn to communicate or infer the intentions of other agents to cooperate, reducing congestion in warehouse aisles without central traffic control.
How does DRL impact the battery life of an AGV?
While the compute load is slightly higher than basic sensors, DRL can optimize motion profiles to be smoother, avoiding unnecessary braking and acceleration. This optimized driving behavior often results in a net positive for energy efficiency and reduced mechanical wear.
Is DRL ready for commercial industrial use?
Yes. While it started in research labs, DRL is now deployed in leading logistics companies for robotic picking arms and autonomous mobile robots. The availability of robust simulation tools and edge AI hardware has made commercialization viable.